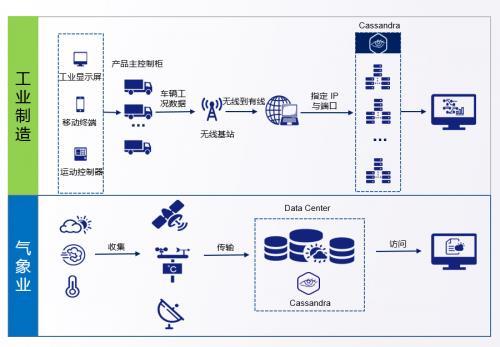
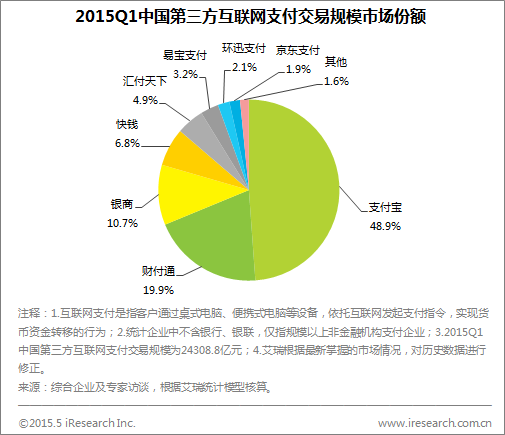
在万物互联的时代,海量的时间序列数据(如传感器读数、设备状态、应用指标等)正以前所未有的速度产生。如何高效、可靠地存储、管理并分析这些数据,成为互联网数据服务领域的关键挑战。时序数据库(Time Series Database, TSDB)应运而生,而Apache IoTDB作为一款专为物联网场景设计的开源时序数据库,正受到越来越多的关注。本文将提供一份时序数据库选型指南,并深度解析Apache IoTDB,同时将其与主流方案进行对比。
一、时序数据库核心选型考量因素
在选择时序数据库时,企业或开发者应重点评估以下几个维度:
- 数据模型与查询能力:是否支持灵活的数据模型(如扁平模型、层次模型)?SQL或类SQL支持是否完善?是否支持丰富的聚合、降采样、时间窗口等时序特有查询?
- 写入与查询性能:高吞吐写入和海量数据点读取的延迟表现是关键指标,需结合自身业务的数据产生频率和查询模式进行评估。
- 存储与压缩效率:时序数据量巨大,高效的数据压缩算法能极大节省存储成本。需考察其压缩比和压缩/解压性能开销。
- 生态系统与集成:是否易于与现有的大数据生态(如Hadoop、Spark、Flink)、流处理框架及可视化工具集成?
- 部署与运维成本:分布式架构的扩展性、稳定性、监控运维工具的成熟度,以及社区和商业支持的力度。
- 特定场景优化:是否针对物联网、运维监控、金融等特定场景有深度优化(如边缘计算支持、乱序数据处理等)。
二、Apache IoTDB深度解析
Apache IoTDB是一个一体化收集、存储、管理与分析物联网时序数据的开源数据库,其设计充分考虑了工业物联网的特点。
核心特性与优势:
- 专为物联网设计的“设备-测点”数据模型:采用树形结构组织时间序列,路径(如
root.ln.wf01.wt01.temperature)能直观反映设备层级关系,非常贴合物联网场景的设备管理逻辑。 - 高吞吐写入与高效压缩:采用列式存储和专用的时间序列编码(如Gorilla, TS-2DIFF)及压缩算法,在保证查询效率的压缩比显著,有效降低存储成本。
- 强大的时序数据处理能力:提供丰富的内置函数进行数据聚合、对齐、填补、采样,并支持用户自定义函数(UDF)。其查询语言兼顾类SQL的易用性和时序查询特性。
- 边云协同架构:轻量级的单机版本适合部署在资源受限的边缘侧进行数据采集和轻量查询;分布式版本则部署在云端,实现海量数据的管理与分析,天然支持边云协同的数据管理策略。
- 完整的生态集成:与Hadoop、Spark、Flink、Grafana、Zeppelin等主流大数据及分析工具无缝集成,便于构建端到端的数据管道。
- 低运维成本:作为Apache顶级项目,拥有活跃的社区。其架构清晰,配置相对简单,降低了运维复杂度。
潜在考量点:
相较于一些更通用的时序数据库(如InfluxDB、TimescaleDB),IoTDB的查询语法需要一定学习成本;其生态虽然完整,但在某些非物联网场景下的第三方工具集成丰富度仍有提升空间。
三、主流时序数据库对比一览
为提供更全面的视角,我们将Apache IoTDB与另两款广受关注的时序数据库进行简要对比:
| 特性维度 | Apache IoTDB | InfluxDB (开源版) | TimescaleDB |
| :---------------- | :------------------------------------------------ | :--------------------------------------------- | :------------------------------------------- |
| 数据模型 | 树状层次结构,专为物联网设备设计 | Measurement, Tags, Fields 扁平模型 | 基于关系模型,使用PostgreSQL的Hypertable |
| 查询语言 | 类SQL,具备时序扩展 | InfluxQL (类SQL), Flux (脚本式) | 标准 PostgreSQL SQL |
| 核心优势 | 边云协同、高压缩比、物联网原生支持 | 写入性能高、生态成熟、简单易用 | 支持完整SQL、与PostgreSQL生态无缝兼容 |
| 典型场景 | 工业物联网、车联网、能源监控 | DevOps监控、应用性能监控(APM)、实时分析 | 复杂业务监控、金融数据、需要复杂关联查询的场景 |
| 部署模式 | 单机版(边缘)、分布式集群(云端) | 单机、开源集群方案有限 | 基于PostgreSQL,可单机可分布式部署 |
| 开源协议 | Apache License 2.0 | MIT (V1.x) / 核心功能开源 (V2.x+) | Apache License 2.0 (社区版) |
四、为您的互联网数据服务选型建议
- 选择Apache IoTDB,如果:您的业务核心是物联网设备接入与管理,数据具有清晰的层级结构(如工厂、生产线、设备、传感器),且对边云协同、存储成本压缩有强烈需求。它在工业互联网、智慧城市等垂直领域表现尤为出色。
- 考虑InfluxDB,如果:您的场景以IT基础设施、应用性能监控为主,需要快速搭建、高吞吐写入,并且依赖其丰富的第三方集成和成熟的社区生态。
- 考虑TimescaleDB,如果:您的团队熟悉PostgreSQL,业务数据不仅限于时序,还需要与关系型数据做复杂关联查询,或者希望复用现有的PG工具链和技能栈。
- 其他考量:对于超大规模、需要极致定制和可控性的场景,也可以评估基于HBase或Cassandra构建的方案(如OpenTSDB),但这通常带来更高的开发和运维复杂度。
###
时序数据库的选型没有绝对的“最佳”,只有“最适合”。Apache IoTDB以其对物联网场景的深度优化和边云协同的独特架构,在快速增长的物联网数据服务市场中占据了重要一席。建议在决策前,根据上述指南明确自身核心需求,并对候选数据库进行概念验证(PoC),从性能、功能、成本等多方面进行实测,从而做出最符合业务长远发展的技术选择。